













| Рубрикатор |  |
 |

| Статьи |  |
ИКС № 06 2010 | |
|
| Дмитрий АВЕРЬЯНОВ Марк КУПЕРМАН | 15 июня 2010 |
Правда «пяти девяток»
Очередные новости о сбоях ИТ-систем на финансовой бирже, повлекших за собой многочасовые простои и колоссальные убытки, вызывают недоумение. В таких компаниях устанавливают отказоустойчивые системы с уровнем готовности не менее «пяти девяток», допустимое время простоя для них – 5 минут в год, но восстановление работоспособности затягивается иногда на всю торговую сессию... Так сколько же реальных «девяток» в 99,999%?

 При обсуждении понятий «ЦОД» или «дата-центр» во главу угла ставятся вопросы надежности и эффективности. «Полное дублирование», «пять девяток», работа в «режиме 24/7» – этими и другими волшебными фразами пестрят страницы ведущих ИТ-журналов. Термин «центр обработки данных» ассоциируется с обеспечением непрерывности бизнеса (Business Continuity), а толерантность, отказоустойчивость, высокая надежность стали обязательным требованием для систем поддержки бизнеса. При проектировании ЦОДов рассчитываются уровни доступности сервисов и данных, а полученные высокие оценки надежности в «пять девяток и выше» считаются неоспоримым аргументом при убеждении заказчика. Однако, как оказалось, вопрос надежности ЦОДа в комплексе с его ИТ-подсистемой настолько слабо изучен, что фактически невозможно количественно обосновать какие-то показатели.
При обсуждении понятий «ЦОД» или «дата-центр» во главу угла ставятся вопросы надежности и эффективности. «Полное дублирование», «пять девяток», работа в «режиме 24/7» – этими и другими волшебными фразами пестрят страницы ведущих ИТ-журналов. Термин «центр обработки данных» ассоциируется с обеспечением непрерывности бизнеса (Business Continuity), а толерантность, отказоустойчивость, высокая надежность стали обязательным требованием для систем поддержки бизнеса. При проектировании ЦОДов рассчитываются уровни доступности сервисов и данных, а полученные высокие оценки надежности в «пять девяток и выше» считаются неоспоримым аргументом при убеждении заказчика. Однако, как оказалось, вопрос надежности ЦОДа в комплексе с его ИТ-подсистемой настолько слабо изучен, что фактически невозможно количественно обосновать какие-то показатели.
Можно использовать субъективные оценки надежности серверной комнаты или дата-центра. Например, при всем блеске и чистоте помещения со стройными рядами монтажных стоек достаточно бывает открыть плитку фальшпола и увидеть запутанный клубок проводов заземления, силовых и информационных кабелей. Имеются и отраслевые стандарты, нормирующие значения надежности. Комплексный стандарт по инфраструктуре ЦОДов, американский TIA-942 (текущая редакция 7.0, февраль 2005 г.) подчеркивает важность задач обеспечения надежности в дата-центре и вводит классификацию на основе минимальных критериев достижения заданных уровней надежности. Стандарт рассматривает четыре уровня – от Tier I до Tier IV с разной степенью готовности инфраструктуры оборудования. Однако в нем даются скорее качественные критерии, включая вид резервирования, например, N+1 или 2(N+1), возможность параллельного выполнения ремонта (обслуживания) и т.п. «Белые страницы» (White paper) Uptime Institute определяют числовые значения готовности (availability) для каждого уровня: например, для Tier IV значение Fault Tolerance (FT) Site Infrastructure составляет 99,995%. Указанные значения справедливы для оценки инфраструктуры ЦОДа, но для оценки готовности вычислительных платформ, СХД и телекоммуникационного оборудования они не предназначены.
Не важно как голосуют, важно как считают
При оценке надежности оборудования в качестве базового параметра принято «время наработки на отказ» – MTBF (mean time between failures). Поэтому скажем несколько слов о легитимности заявленной наработки на отказ отдельных компонентов. Например, для жестких дисков некоторые известные производители указывают значения MTBF свыше миллиона часов! Не скромничают в своих оценках и производители других компонентов ЦОДов, как ИТ-оборудования, так и инженерной составляющей. Часто вопрос об этой величине ставит вендора в тупик, не говоря уж подтверждении заявленных значений. Не будем здесь спорить с производителями серверных платформ, СХД, инфраструктурных компонентов ЦОДов о верности декларируемых значений MTBF; отметим только, что данные для объективных расчетов надежности следует брать не у производителя, а у независимых испытательных лабораторий, так как объективную оценку может дать только внешний аудит. Поэтому сосредоточимся на последующих расчетах.
Основная стратегия повышения надежности ЦОДа и его подсистем для получения желаемых четырех или пяти «девяток» состоит в поэлементном резервировании (структурном резервировании). Однако информация по этому вопросу, кроме самого заявления о необходимости резервирования в ЦОДах (причем только для инженерной инфраструктуры) и качественных критериев такого резервирования, в материалах TIA-942 и Uptime Institute отсутствует. Аналогично складывается ситуация с оценкой надежности отказоустойчивых компьютеров и систем хранения. Нет ни признанных, ни хотя бы опубликованных референтных моделей или методик расчета надежности резервируемых структур применительно к ЦОДам в целом, инфраструктуре ЦОДа, ИТ-оборудованию (включая вычислительные кластеры, в том числе геокластеры), СХД, а также к резервным центрам. Производители кластеров и СХД не показывают свои модели. Более того, вендоры и заказчики скрывают факты отказов и простоев, причем независимо от того, был ли это отказ сервера или системы питания. Какой, например, банк будет говорить об этом, подвергая риску свою репутацию?
Как обосновываются «пять девяток»? Вендоры часто ссылаются на статистику отказов, но при этом, указав пять или шесть «девяток», порой заявляют, что цифра взята «по аналогии» с предшествующими системами, которые тестировались десятилетиями и показали «превосходную» надежность. Таким образом, недавно вышедшая на рынок очередная модель «по наследству» получает накопленный опыт в части надежности. А исходную статистику и рабочие журналы вендоры не открывают.
Отсутствие нормирующих и руководящих документов или хотя бы обсуждаемых моделей приводит к следующему. При обосновании требуемой надежности слева кладется ТЗ с заявленными заказчиком требованиями к надежности проектируемой системы. Справа – стопка справочников с формулами расчета надежности (справочники, как правило, 70-х и 80-х гг. издания, так как сегодня оценка надежности перестала быть «популярной темой»). В середине проектировщик раскладывает «удобные» модели, обеспечивающие стыковку правой и левой части. Причем выбор модели ничем не регламентирован, так как ни ITIL, ни TIA-942, ни другие признанные руководства и правила не дают указаний и разъяснений, как считать, модели какого класса использовать, что необходимо учитывать, а чем можно пренебречь. Продемонстрируем типовую схему получения нужных результатов на примере.
Традиционный расчет надежности
Для доказательства высокой проектной оценки надежности часто применяют следующий «удобный» расчет дублированной группы серверов. Используется марковская цепь, приведенная на рисунке. В качестве параметров модели задаются интенсивности отказов λ и восстановления µ. Отказом считается выход из строя обоих узлов: состояние «2».
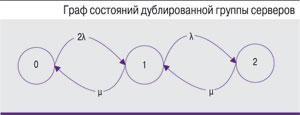 При расчете такой модели получаются явно завышенные значения показателей надежности, не отражающие реальную надежность системы. При исходных значениях интенсивности отказов λ = 0,00005 1/ч (наработка на отказ составляет 20 000 ч) и интенсивности восстановления µ = 0,25 1/ч (4 ч на восстановление) получим из расчета графа значение коэффициента готовности Кг = 0,99999992 (семь девяток). Подчеркнем, что взятая наработка в 20 тыс. ч – это нижняя планка MTBF серверных платформ, обычно для серверов указывают значения 50–100 тыс. ч и, следовательно, результаты получаются даже более «хорошими». Отсюда возникает резонный вопрос: что лучше – подтвержденные три «девятки» или маркетинговые шесть? Кроме того, «пять девяток» декларируются, как правило, только для платформы; для конечной системы значения готовности будут совсем другими, не говоря уж о значениях RTO (Recovery Time Objective, целевое время восстановления).
При расчете такой модели получаются явно завышенные значения показателей надежности, не отражающие реальную надежность системы. При исходных значениях интенсивности отказов λ = 0,00005 1/ч (наработка на отказ составляет 20 000 ч) и интенсивности восстановления µ = 0,25 1/ч (4 ч на восстановление) получим из расчета графа значение коэффициента готовности Кг = 0,99999992 (семь девяток). Подчеркнем, что взятая наработка в 20 тыс. ч – это нижняя планка MTBF серверных платформ, обычно для серверов указывают значения 50–100 тыс. ч и, следовательно, результаты получаются даже более «хорошими». Отсюда возникает резонный вопрос: что лучше – подтвержденные три «девятки» или маркетинговые шесть? Кроме того, «пять девяток» декларируются, как правило, только для платформы; для конечной системы значения готовности будут совсем другими, не говоря уж о значениях RTO (Recovery Time Objective, целевое время восстановления).
По приведенной выше модели ведется расчет и других резервируемых систем ЦОД: от телекоммуникационного оборудования до систем бесперебойного питания.
Человеческий фактор
Работоспособность ЦОДа зависит от множества факторов. Не будем здесь рассматривать внешние факторы, такие как природные катаклизмы и техногенные катастрофы, а также хакерские атаки. Сосредоточимся только на внутренних. Очевидно, что рассмотренная выше модель дублированной группы является слишком упрощенной и неадекватна процессам, которые реально происходят в вычислительных системах, будь то сетевые кластеры или отказоустойчивые системы. Более того, в материалах Uptime Institute подчеркивается, что оценивать надежность ЦОДа только на основе MTBF недостаточно, так как существенный вклад в доступность ЦОДа вносит человеческий фактор. Исследования, помимо статистического анализа отказов оборудования, должны также учитывать человеческие поступки и решения. Поэтому, несмотря на более чем двукратное резервирование (удвоенное «N+1»), значение готовности для максимального уровня ЦОДа (Tier IV) составляет только 99,995.
Следовательно, максимальный нормированный уровень надежности инфраструктуры FT-ЦОДа (отказо-устойчивого ЦОДа) уже оказывается ниже уровня вычислительных отказоустойчивых (FT) и ряда кластерных (HA-cluster) платформ. Результирующее значение, полученное последовательным соединением показателей основных (ИТ) и обеспечивающих компонентов, составит «меньше меньшего» и никогда – во всяком случае, теоретически – не достигнет заветных «пяти девяток» на ЦОД в целом. Таким образом, какую бы готовность ни имели вычислительные отказоустойчивые платформы, пусть даже семь и более «девяток» (полученные к тому же без учета человеческого фактора), следует ожидать итоговую цифру существенно менее 99,99 даже для Tier IV. Отметим, что данные об успешной сертификации российского ЦОДа на Tier IV авторам пока не встречались. Более того, статистика Uptime Institute свидетельствует, что уже мгновенное пропадание питания отключает информационные сервисы в среднем на 4 ч (Uptime Institute, Tier Classifications Define Site Infrastructure Performance).
Спорным является и вопрос о том, что предпочесть: более надежное оборудование или более качественные планы восстановления после аварии (DRP, disaster recovery plan) и сценарии предупреждения аварийных ситуаций, включая оптимизацию RPO (Recovery Point Objective, временной интервал до сбоя, данные за который будут потеряны). Существуют и графические формы представления, отражающие информацию о надежности систем, например, блок-схема надежности (Reliability Block Diagram, RBD), анализ дерева событий (Event Tree Analysis) или схема дерева отказов (Fault Tree diagram). Качество проработки таких мероприятий также определяет время простоя и конечную надежность системы.
В этой статье мы лишь бегло, штрихом обозначили часть проблемных вопросов оценки надежности, включая надежность ИТ-оборудования и инфраструктуры ЦОДа. За скобками остались вопросы надежности ПО, живучести в условиях воздействия на систему внешних факторов, включая катастрофоустойчивость. Но, как показано выше, обеспечить в реальной системе «пять девяток», во всяком случае, в рамках одного ЦОДа, представляется маловероятным.
Может быть, и не нужно точных оценок надежности, достаточно общих слов о ее достаточности? Однако если непрерывность бизнеса определяется надежностью ИТ и бизнес считает убытки от простоя, причем с высокой точностью, то почему комплексная количественная оценка надежности не востребована? Видимо, со временем придет понимание того, что нужно правильно оценивать надежность систем еще на этапе проектирования, с учетом ИТ-оборудования, ПО и инфраструктуры ЦОДа, а также ряд внешних факторов. Что дешевле: вначале провести адекватную оценку надежности системы и понимать, на что можно рассчитывать и какие SLA гарантировать, или потом считать убытки от простоя?
Еще не так давно вопросам практической оценки надежности проектируемых систем и развитию самой теории надежности уделялось повышенное внимание. Как известно, новое – это хорошо забытое старое, так что вопросы обеспечения надежности, реальной количественной ее оценки, безусловно, будут снова востребованы и адаптированы под современные требования. икс