













| Рубрикатор |  |
 |

| Статьи | |
|
| Николай НОСОВ | 14 августа 2017 |
Визуализация данных в интернете вещей
Большие данные выдвигают особые требования к средствам визуализации результатов анализа в режиме реального времени.
В марте 1979 года произошла крупнейшая в истории атомной энергетики США авария. На втором энергоблоке станции АЭС Три-Майл-Айленд по причине вовремя не обнаруженной утечки теплоносителя произошло расплавление около 50 % активной зоны реактора, после чего энергоблок так и не был восстановлен. Причиной аварии послужили ошибочные действия персонала, который не разобрался в изначально не такой уж серьезной технической проблеме. Принять правильные решения было нелегко – в первые минуты аварии на щите управления сработала аварийная сигнализация по более ста параметрам, которые никак не были ранжированы по степени значимости. Принтер, печатавший диагностические данные, выдавал лишь одну строку в четыре секунды и в итоге отстал на два часа от реальных событий. Индикаторы не были логически сгруппированы – чтобы посмотреть некоторые необходимые для анализа параметры приходилось обходить информационные панели и искать датчики в шкафах управления.
Авария наглядно показала, к чему могут привести недостатки человеко-машинного интерфейса и важность проблемы визуализации данных, которые должны представлятcя автоматизированной системой в удобном и понятном для оператора виде.
Интернет вещей – один из основных трендов развития современных ИТ
По большому счету интернет вещей (IoT) – это все та же автоматизация, но на новом витке развития технологий, когда за счет современных средств аналитики удается существенно повысить степень утилизации различных объединенных в пулы устройств. Это дает значительный экономический эффект. По прогнозам аналитиков Accenture вклад промышленного интернета вещей (IIoT) в мировое производство к 2030 году составит $14,2 триллиона, что повысит уровень мирового ВВП на 11%.
Ключевыми признаками IIoT являются: вертикальная интеграция процессов производственных систем внутри предприятия, горизонтальная интеграция предприятий до уровня производственных систем и управление полным жизненным циклом (от проектирования до вывода из эксплуатации) продуктов через «цифровых двойников» (удаленный мониторинг, предсказание состояния и управление).
Основными компонентами IoT являются средства подключения не-ИКТ-устройств (SDK-коннекторы для подключения через механизм API к облаку управления), платформа сбора и анализа данных, обеспечивающая API-интеграцию с облачными бизнес-сервисами (SaaS), системы хранения, анализа и визуализации данных.
Немного о визуализации
Сначала определимся с термином. Визуализация данных (ВД) — это представление данных в виде, который обеспечивает наиболее эффективную работу человека по их изучению. Визуализация применяется при представлении статистики и отчетов (данных за некий период времени, которые показываются вместе), как справочная информация, поясняющая полученные данные, и как интерактивные сервисы, где инфографика является частью функциональности. Например, при использовании в диспетчерских карт территорий или картограмм устройств.
Если проводить классификацию по объектам, то стоит выделить визуализацию числовых данных: (детерминированные зависимости – графики, диаграммы, временные ряды; статистические распределения – гистограммы, матрицы диаграмм рассеяния); иерархий (диаграммы узлы-связи, дендрограммы), сетей (графы, дуговые диаграммы) и геовизуализацию (карты, картограммы).
В отличие от обычного графического интерфейса, средства ВД обеспечивают способность одновременного отображения большого числа разнотипных данных, возможность их сравнения, выделения выпадающих значений. Другое преимущество – возможность легко и быстро перемещаться между микро- и макропредставлением и просматривать связи с контекстом.
Требования к системам визуализации данных в IoT
Обработка больших объемов данных включает этапы: сбора и первичной обработки информации, загрузку в хранилище, анализ данных и предоставление результатов в удобном для восприятия виде. Требование обработки в режиме реального времени делает задачу еще более сложной. Традиционные NoSQL базы данных обрабатывают запросы слишком медленно, так что целесообразно иметь еще и базу данных непосредственно в оперативной памяти сервера (in-memory). Если данных требуется много – масштабируемое распределенное (in-memory-data-grid) по оперативной памяти нескольких серверов кластера хранилище.
При создании информационной системы обязательно должны учитываться особенности объекта. Аналитик должен быть не только специалистом в области Big Data, но и хорошо знать предметную область, а в идеале быть экспертом, детально разбирающимся в анализируемых и прогнозируемых процессах, что помогает понять – какие данные нужны, как проводить их очистку, выбрать методы анализа и интерпретировать результаты.
Чтобы избежать ситуации, приведшей к аварии на американской АЭС, требуется тщательно подойти к вопросам ВД. Оператору нужно иметь на информационной панели (дашборд) удобное представление наиболее важных показателей и возможность своевременного выявления негативных тенденций и проблем. В его распоряжении должны быть средства детального анализа ситуации и оперативного формирования подробных отчетов, включая прогностические системы, помогающие принять оптимальное решение.
Пользователю нужна возможность самостоятельной настройки параметров поиска и передачи результатов, создания собственной панели наблюдения (дашборд), выстраивания визуализаций и панелей данных в предпочтении необходимости выполнения операций. Ведь этим все чаще занимаются не программисты, а специалисты в конкретной области, проводящие конечную настройку решения.
Система должна обеспечивать возможность поиска данных в интерактивном режиме с использованием фильтров, быстро определять аномалии и выбросы в больших и быстроменяющихся данных, давать разнообразные способы представления статических данных и временных рядов.
Очень важна скорость обработки информации, потоковая визуализация информации. Нет ли чего-то необычного в поступающих данных? Какой может произойти инцидент и через какое время? Система должна сигнализировать о выходе параметров за заданные пределы и о реакции на это автоматизированных комплексов.
Данные датчиков являются непрерывными и имеют разные требования по времени съема информации (миллисекунды, наносекунды). Следует учитывать, что сигналы появляются нерегулярно, иметь возможность анализа во временных окнах появления сигнала, в различных срезах и с возможностью их повторного воспроизведения (текущих, этого дня или из архива). Система должна менять графическое представление в режиме реального времени, обеспечивать возможность детализации без остановки живого графического представления данных
Нужно иметь возможность прогноза по потоковым данным, использования предиктивных моделей, основанных на шаблонах данных о поведении в прошлом, использовать чужой накопленный опыт (прогностическое обслуживание, умная логистика, обнаружение клинических паттернов и т. д.)
Сложные форматы данных, поступающих с датчиков, требуют возможности поддержки разных стандартов и сведения информации для дальнейшего преобразования и обработки. Кроме этого нужно обрабатывать данные из SQL и NоSQL баз данных. Причем система должна обеспечивать к ним единый интерфейс, а выполнение сложноструктурированных запросов, не должно требовать от пользователя знания языка SQL
Важным требованием к системам визуализации является поддержка геопространственной аналитики в режиме реального времени: географических карт, пользовательских SVG (Scalable Vector Graphics — масштабируемая векторная графика) файлов, а также возможность воспроизведение архивных записей.
Часто требуются возможности экспорта результата в различные форматы (CVS, JPEG, PDF, фрагменты кода для постановки непосредственно на web-страницы) и средства объединения с иными приложениями посредством API. Не стоит забывать о популярности мобильных приложений и возможности адаптации изображения к экрану портативного устройства. И конечно, система должна иметь возможность обработки требуемого объема информации, который может быть очень большим.
Самостоятельная разработка

Эксперт по управлению данными МТС Юрий Петров выделил несколько подходов к построению систем анализа и визуализации данных в IoT. Для сбора данных в реальном времени и гарантированной доставки сообщений можно использовать распределенные отказоустойчивые потоковые платформы (kafka.apache.org). Важные для работы системы автоматизации события (например, превышение параметра, измеряемого датчиком некоторого порогового значения) извлекается из потока данных и поступает в топик (таблицу) платформы Kafka (аналог корпоративной шины), где хранится установленное время. Из этого топика информация может быть считана и передана в брокер сообщений (например redis.io, aerospike.com) или в in-memory NoSQL БД (например tarantool.org, couchbase.com). Поверх такой in-memory NoSQL БД удобно строить аналитику реального времени.
Так же в качестве in-memory NoSQL БД можно использовать гибридный распределенный кеш (In-Memory Data Grid), такой как hazelcast.org, infinispan.org или Oracle Coherence. Для работы с сенсорами удобно использовать гибридные базы данных временных рядов (Time Series БД), предназначенные специально для IoT (influxdata.com, crate.io).
Для дальнейшей работы с данными можно использовать высокопроизводительные распределенные NoSQL базы данных, например Druid или более «классические» – Cassandra, HBase, MongoDB, OrientDB, или даже простые контейнеры Hadoop (Avro, ORC, Parquet).
Следующий шаг – анализ и визуализации данных. При анализе ad-hoc (узкоспециализированные запросы для решения единоразовой проблемы) активностей и прототипировании данные можно визуализировать непосредственно во время разработки кода на Java, Python, R или Scala. В случае необходимости распределенных вычислений на кластере Hadoop не обойтись без использования Apache Spark. В качестве среды разработки часто используются web-платформы Jupyter или Zeppelin.
Среди инструментов визуализации данных стоит выделить самую популярную библиотеку для языка R – ggplot2. Так же стоит отметить пакет Ggally. Он является расширением R пакета ggplot2 – системы построения графиков, в который добавлены несколько функций для сокращения сложности геометрических объектов путем преобразования данных. Также добавлены такие средства визуализации, как матрицы парных графиков, матрицы диаграмм, представления в параллельных координатах, функции для отображения сетей.
Приложения для визуализации также создаются на языке Python. Для этого языка имеется библиотека Matplotlib, с помощью которой можно проводить ВД с помощью 2D и 3D графики (Python’s Matplot lib). Имеется также русскоязычный ресурс по Matplotlib.
Для разработки WEB-приложений наиболее популярной библиотекой является D3.js. Это Open Source библиотека JavaScript для работы с документами на основе данных. В сравнении с другими JS-Framework, D3.js обладает гораздо большими возможностями по ВД.
Для анализа и визуализации данных не обязательно писать программы. Можно использовать уже готовые пакеты. Наиболее популярные web-based платформы для real-time визуализации данных, мониторинга и анализа временных рядов: Grafana, Kibana и Zabbix.
Если продолжать говорить о решениях Open Source, то для создания ad-hoc и быстрого прототипирования используется web-based BI приложение Superset .
Проприетарные системы визуализации IoT
Конечно, все можно сделать самому, используя решения Open Source, как это наглядно показал Юрий Петров, но далеко не все обладают необходимой экспертизой для разработки и ресурсами для дальнейшего сопровождения систем. Проще использовать готовые системы. Тем более, что на рынке они есть.
Если у клиента типовые, хорошо изученные задачи, то можно не изобретать велосипед, а использовать системы real-time визуализации коммерческих платформ IoT.
В настоящее время в число лидеров по оценкам Forrester входят IBM (IBM Watson IoT Platform), PTC (ThingWorx platform), GE (Predix), Microsoft (Microsoft Azure IoT Suite), AWS (AWS IoT), SAP.
| The Forrester Wave™: IoT Software Platforms, Q4 2016 |
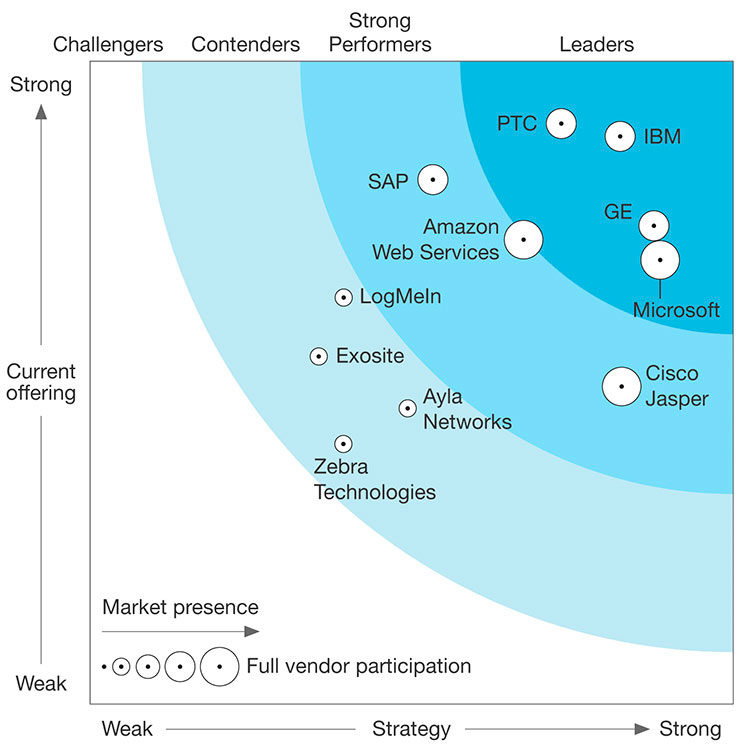 |
В России используются системы визуализации платформ GE (энергетика), Cisco (телеком), MS (ритейл, транспорт), PTC (сельское хозяйство и “умный дом»), Huawei (телеком), SAP (энергетика, транспорт).

– Набор решений SAP для поддержки интернета вещей называется SAP Leonardo Internet of Things (IoT), – пояснил Денис Савкин, руководитель центра экспертизы по решениям и технологиям SAP СНГ. – Сбору, обработке и доставке данных в этом наборе посвящен целый ряд продуктов, объединенных в два блока SAP Leonardo Foundation и SAP Leonardo for Edge Computing. Основные функции, реализуемые с помощью данного ПО - это сбор данных с устройств, их промежуточное накапливание, предварительная обработка (агрегирование и потоковая аналитика) и гарантированная доставка в центральную БД на промежуточных узлах сети. В центральной базе данных (SAP Cloud Platform или SAP HANA у клиента) происходит учет устройств (ведение цифровых двойников), потоковая обработка событий, передача данных в бизнес-системы, анализ и визуализация.
Для сбора и обработки данных SAP использует собственную платформу хранения и обработки данных SAP HANA – in-memory реляционную систему управления базами данных. SAP HANA по умолчанию включает в себя ряд функций, таких как обработка временных рядов и обработка потоков данных (в т.ч. процессор событий). SAP HANA может размещаться в облаке SAP или партнеров или в дата-центре клиента. Облачная платформа SAP (SAP Cloud Platform) включает в себя также брокеры сообщений, такие как redis.io, RabbitMQ и некоторые другие, доступные в парадигме Cloud Foundry.
Дополнительно SAP предлагает своим заказчикам сервисы других баз данных, таких как Sybase ASE, SAP MaxDB или доступных по лицензии Open Source, например MongoDB, PostgresSQL. Кроме того, SAP предлагает сервис Hadoop в облаке, а также SAP Vora – in-memory средство для кардинального ускорения обработки запросов к Hadoop, снабженный также дополнительными инструментами, такими как обработка графов, документов, временных рядов.
Основным инструментом ad-hoc анализа в портфеле SAP является SAP Lumira. Это решение для визуализации данных позволяет создавать интерактивные схемы, диаграммы и инфографику. Основная целевая группа решения – бизнес-пользователи, не обладающие серьезной IT-подготовкой.
В последнее время на первый план выходит инструментарий прогнозной (предиктивной) аналитики. В линейке BI-продуктов SAP – это SAP Predictive Analytics, включающий в себя целый набор программных пакетов, таких как средства автоматизации построения, обучения и запуска предиктивных моделей; «классические» методы машинного обучения, предназначенные для экспертов – дата-сайентистов; автоматизированная прогнозная аналитика. Все эти пакеты снабжены средствами визуализации данных и результата построения и обработки моделей, позволяющими значительно повысить производительность труда аналитика.
Среди проприетарных решений визуализации наибольшей популярностью в России пользуется Tableau, которая часто используется как корпоративная BI-платформа, ориентированная на работу с любыми данными. Еще одна популярная система – Qlik. Другой лидер мирового рынка Bi по оценкам Gartner – MS Power BI, по мнению Юрия Петрова, теряет популярность в России.
Российские платформы
На рынке появились и российские платформы визуализации. Если BI система Prognoz Platform предназначена для визуализации только аналитических данных, то в появившейся в июле 2017 г. платформе Visiology 2.0 есть возможность и real-time обработки. Разработанная российской компанией Visiology in-memory база данных ViQube дает возможность добавления и удаления данных в режиме реального времени, причем для этого не требуется полная перезагрузка системы.

Объем данных in-memory базы данных ограничен размером памяти сервера. Остальные данные можно при необходимости подкачивать из кластера Hadoop, но это сильно сказывается на производительности системы. По словам генерального директора Visiology Ивана Вахмянина разработка распределенной in-memory базы данных не входит в планы компании, так как в большинстве решаемых задач объема памяти сервера хватает для размещения анализируемых данных.
В новой версии была создана встроенная система веб-форм для быстрой автоматизации сбора данных и организована интеграция платформы со стеком технологий Big Data. Ограниченные стандартные возможности визуализации компенсируются поддержкой языков Pyton, R и #C, так что клиенты могут делать кастомизированные дашборды для своих задач используя внешние библиотеки визуализации.
К сожалению, бизнес-модель компании не подразумевает использования платформы Visiology 2.0 по сервисной модели. Система ориентирована на крупных клиентов – органы власти, ситуационные центры, телеком, предприятия нефтяной и энергетической промышленности.

Заключение
По прогнозам iKS-Consulting, в 2025 году почти 20% генерируемых данных будут представлять собой информацию, получаемую в режиме реального времени.
Ее визуализация – достаточно новое, но быстро развивающееся направление ИТ. Выбор есть: можно взять проприетарные платформы крупных западных вендоров; появились российские игроки, если у компании есть хорошие программисты – можно создать систему на средствах Open Source. Уже сейчас, как отметил координатор Big Big Data Group Олег Фатеев, специалисты по визуализации считаются самыми высокооплачиваемыми в области больших данных. И спрос на них будет только расти.