













| Рубрикатор |  |
 |

Реклама
| Статьи | |
|
| Артем МЕЛИКДЖАНЯН Даниил КАНЕВСКИЙ | 14 ноября 2019 |
Как не потеряться в многообразии SKU в чеках, делать аналитику и прогнозировать
Адекватное сопоставление наименований товаров (Stock Keeping Unit, «складская учетная единица») в контрольно-кассовых чеках позволяет анализировать товарный ассортимент, уровень цен, географию продаж, изучать динамику изменений и делать прогнозы.
Сегодня операторы фискальных данных, в том числе «Такском», предлагают клиентам новый инструмент для развития бизнеса – Big Data analytics. Данные ОФД можно использовать для оценки эффективности рекламы, анализа потребительской корзины, сравнения своих продаж со средними показателями на рынке, оценки эффективности работы кассиров. И это далеко не полный спектр возможностей, открывающихся перед бизнесом.
Товар один, наименований – сотни
Чтобы предоставлять качественную аналитику, нужно решить основную проблему при работе с чеками – вариативность наименований одного и того же товара в различных торговых точках.
Представим, вы купили абсолютно одинаковые бутылки «Кока-Колы» в нескольких магазинах: «Ашане», «Магните» и «Пятерочке». Товары идентичны, однако их наименования в полученных вами чеках разные. Более того, для одного и того же товара могут быть сотни вариантов наименований в чеках. Возникает вопрос: как быстро и точно группировать их, если это один и тот же товар?
На помощь придет база знаний
При внесении наименования товара в торговую систему люди опираются на одни и те же его ключевые свойства. Этот факт и использует алгоритм, разработанный в компании GoodsForecast, на основе которого формируется база знаний, позволяющая определить уникальную специфику наименований различных товаров.
Как это выглядит на практике? К примеру, перед ОФД поставлена задача проанализировать продажи творожного десерта «Чудо». SKU, т.е. уникальное наименование товара, звучит как «Чудо творожок воздушный с вареньем вишня-черешня 4%, 100 г». Это своеобразный эталон, по которому ОФД ищет товар в кассовых чеках. Но фактически в фискальных документах отражено куда больше вариантов: «Десерт молоч с твор кр Чудо 4% 100 г вишня», «Творожок Чудо с джемом вишня черешня 4,0% 100 г ОАО Вимм Билль Данн»...
Каждое слово из SKU становится вершиной графа базы знаний. В рассматриваемом случае это будут слова «Чудо», «творожок», «воздушный», «4%» и т.д.
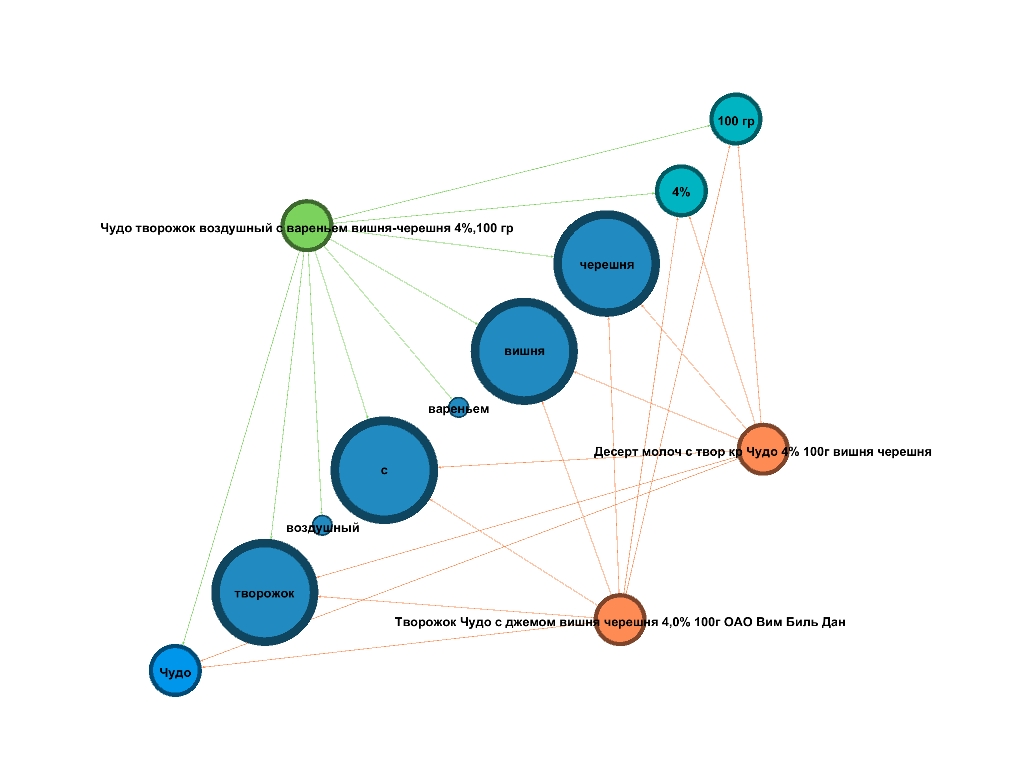
Алгоритм учитывает частоту совместного расположения отдельных слов в базе знаний чеков, обнаруженные торговые марки и количественные показатели (вес, жирность продукта и т.п.). Благодаря этому при сопоставлении можно сделать вывод, что это один и тот же товар, хотя и указан в чеках по-разному.
Информация в базе знаний регулярно пополняется, формируя словари брендов, единиц измерения, русского языка, синонимов-алиасов (gold = золото = голд). Это увеличивает процент точности сопоставления.
Долгосрочное решение: единый классификатор товаров
Разработанные алгоритмы сопоставления наименований товаров существенно повышают качество информации, содержащейся в контрольно-кассовых чеках. Если решение задачи сопоставления наименований товаров в узком смысле предусматривает предоставление качественной аналитики в ответ на заказ клиента, то в широком смысле ее решение позволит создать единый динамический справочник и классификатор товаров.
У разных заказчиков и исполнителей разный подход к классификации. Наличие универсального каталога, опираясь на термины которого заказчик ставит задачи, снимает многие проблемы. Поскольку в новом подходе графы базы знаний выстраиваются автоматически, то классификатор можно сделать динамическим. Это долгосрочное решение проблемы сопоставления.
Артем Меликджанян, руководитель департамента развития бизнеса, ОФД «Такском»
Даниил Каневский, директор по аналитике,
GoodsForecast
Заметили неточность или опечатку в тексте? Выделите её мышкой и нажмите: Ctrl + Enter. Спасибо!