











| Рубрикатор |  |
 |
| Статьи |  |
ИКС № 01-02 2014 | |
|
| Сергей ЗОЛОТАРЕВ | 27 января 2014 |
Три кита «больших данных»
За маркетинговым термином Big Data стоят три известных не первый год технологических направления, стек из которых закрывает все потребности крупных компаний в работе с «большими данными».
 Первая технология, обеспечивающая работу с Big Data, а точнее, обработку больших массивов структурированных данных, MPP (massive parallel processing, технология массивно-параллельной обработки данных), появилась лет 20–25 назад. На сегодняшний день она признана аналитиками предпочтительной для создания корпоративных хранилищ. Это полностью сформировавшаяся область знаний, которую продвигают на глобальном рынке 3–4 игрока, в том числе и компания Pivotal.
Первая технология, обеспечивающая работу с Big Data, а точнее, обработку больших массивов структурированных данных, MPP (massive parallel processing, технология массивно-параллельной обработки данных), появилась лет 20–25 назад. На сегодняшний день она признана аналитиками предпочтительной для создания корпоративных хранилищ. Это полностью сформировавшаяся область знаний, которую продвигают на глобальном рынке 3–4 игрока, в том числе и компания Pivotal.
Для решения второго класса задач – обработки больших объемов неструктурированных или слабо структурированных данных – используется технология Hadoop, зародившаяся более 10 лет назад в интернет-компаниях, которым важно было совместить возможности дешевого хранения данных и очень быстрого поиска информации. Вот почему Apache Hadoop и близкие к ней технологии представляют собой симбиоз файловой системы и некоего framework для обработки поисковых задач.
Есть еще третья область – самая новая и динамично развивающаяся, связанная с обработкой даже не «больших», а «быстрых данных». Ее полностью закрывает технология обработки данных в оперативной памяти, In-Memory Database.
Обратите внимание, каждая из технологий идеально подходит для обработки какого-то одного вида данных. Сынтегрировав их в один стек, удалось предложить заказчику платформу, универсальную как в плане типов обрабатываемых данных, так и скорости их обработки.
В целом аппаратная платформа под Big Data по сравнению с традиционными ИТ-системами достаточно проста, она представляет собой многоузловой кластер, а следовательно, отказоустойчива и линейно масштабируется.
Big Data для телекома
Наибольшую пользу решения для обработки «больших данных» сегодня могут принести телекоммуникационным компаниям, чему способствует сама конкурентная ситуация в этом сегменте рынка, отличающемся высоким насыщением. Телеком-операторы во всем мире стремятся, с одной стороны, снизить затраты, оптимизировать производительность и эффективность работы сетевого оборудования, с другой стороны, предлагать абонентам больше услуг на уже задействованной инфраструктуре. И, как показывает проект EMC в области Big Data у одного из крупнейших европейских телеком-операторов, кросс-анализ больших данных позволяет им все это делать.
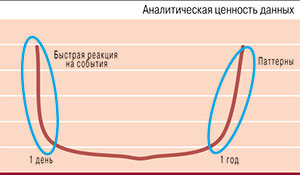 Однако при этом важно понимать, что только универсальная платформа для обработки всех типов «больших данных» способна обеспечить бизнесу их максимальную аналитическую ценность. Дело в том, что информация наиболее ценна для анализа в интервалах до одного дня и после одного года (см. рисунок). Проанализировав данные, поступающие в течение дня, специалисты оператора могут предпринять какие-то действия и скорректировать ситуацию. А анализ информации, собранной за год, позволит выявить паттерны и на их основе моделировать будущее. В первом случае наиболее эффективной будет технология In-Memory, обеспечивающая обработку данных в режиме, близком к реальному времени, а во втором – Hadoop, только с ее помощью сегодня можно экономично хранить и обрабатывать объемы данных за пределами одного года. На текущий момент большинство аналитических систем работает в диапазоне от одного дня до года, потому что данных много и хранить их очень дорого.
Однако при этом важно понимать, что только универсальная платформа для обработки всех типов «больших данных» способна обеспечить бизнесу их максимальную аналитическую ценность. Дело в том, что информация наиболее ценна для анализа в интервалах до одного дня и после одного года (см. рисунок). Проанализировав данные, поступающие в течение дня, специалисты оператора могут предпринять какие-то действия и скорректировать ситуацию. А анализ информации, собранной за год, позволит выявить паттерны и на их основе моделировать будущее. В первом случае наиболее эффективной будет технология In-Memory, обеспечивающая обработку данных в режиме, близком к реальному времени, а во втором – Hadoop, только с ее помощью сегодня можно экономично хранить и обрабатывать объемы данных за пределами одного года. На текущий момент большинство аналитических систем работает в диапазоне от одного дня до года, потому что данных много и хранить их очень дорого.
Впрочем, в приложении к телекому и In-Memory, и Hadoop приобретают новые роли. Так, Hadoop, которая в общем случае позиционируется как недорогая технология для длительного хранения огромных объемов информации, в компаниях этого сектора сейчас эффективно используется в качестве универсального ETL-уровня для создания единого места, куда сбрасываются и где затем сортируются разноформатные данные: часть идет в хранилище, другая направляется в аналитические витрины, третья остается в Hadoop на долговременное хранение.
У технологии In-Memory в телеком-компаниях тоже появилось второе назначение – это уровень mediation. На этом уровне с ее помощью можно в режиме онлайн получать сырые данные с технологического оборудования, которые ранее собирали с помощью специальных проприетарных приложений, анализировать их «на лету» и очень быстро реагировать на экстренные события.
На сегодняшний день в мире существует несколько крупных хранилищ данных, к примеру, хранилище для Skype, которое мы поддерживаем, имеет объем порядка 5–6 Пбайт. Именно на таких объемах себя хорошо зарекомендовали MPP-платформы. В России релевантный для операторов большой тройки объем информации я бы оценил величиной от 1,5 до 3 Пбайт, и выйти на него они могут уже за 2–3 года.
Сценарии выбора
Примеров внедрения технологий Big Data в российских компаниях пока немного, но мы уже видим, как на рынке формируются два основных сценария выбора подобных решений. Первый из них реализуется, когда потенциальные заказчики понимают, какие преимущества для бизнеса они получат за счет обработки больших объемов информации, знают об опыте зарубежных коллег по рынку и фактически копируют его. Как правило, в этом случае в компании есть люди, которые могут сформулировать задачу: какой тип информации они хотят извлекать из тех или иных данных, как с ней планируют работать дальше, – и попросить предложить им архитектурное решение, которое обеспечит достижение заданных показателей времени отклика (response time), доступности информации. Надо признать, что такой сценарий, к сожалению, встречается редко.
Второй сценарий реализуется, если лица, принимающие решения, видят, что в мире сейчас все интересуются темой «больших данных». Они создают инициативную группу, выделяют Big Data как стратегическое направление и начинают его прорабатывать. Вот на этом этапе перед ними встают вопросы методологии. Наша методология, например, позволяет составить «дорожную карту», показывающую маршрут каждого заказчика к внедрению этих технологий, подобрать правильные бизнес-инициативы, облачить их в рамки проекта, сделать прототип и продемонстрировать его возможности.
Критерии успешности
Правильно сформировать ожидания и потом иметь возможность оценить результат очень важно. По нашей практике, результаты внедрения технологий Big Data в компаниях пытаются анализировать в нескольких плоскостях.
Самая простая – плоскость ИТ-бюджета. Предположим, что стоимость подготовки той или иной отчетности в компании ежегодно увеличивается на 20% по причине роста объемов данных в корпоративном хранилище, построенном на традиционных технологиях. Это не устраивает ее ИТ-директора, и он начинает поиск альтернативных вариантов. В этом случае оценить эффект от перехода на новые технологии нетрудно: по сравнению с традиционной технология массово-параллельного процессинга почти в два раза дешевле, с точки зрения как капитальных, так и операционных затрат.
В случае с OPEX выигрыш может быть еще больше, поскольку используются не проприетарные системы, а стандартные платформы Intel, притом, как показывают наши проекты, хранилище с MPP-архитектурой в среднем в 10 раз быстрее традиционных. То есть бизнес может сам оценить эффект от ускорения формирования аналитических справок и аналитических отчетов.
Существует методология оценки эффективности комплексного проекта по внедрению технологий Big Data. Например, в телеком-компании получателями выгод от его реализации могут выступать различные департаменты: технический, департамент сбора доходов, департаменты маркетинга и программ лояльности клиентов. Для их оценки у каждого оператора уже выработаны какие-то метрики, например Conversion Rate в маркетинге. Наша задача только показать им, кто в компании может быть выгодоприобретателем от внедрения технологии Big Data.
* * *
В США сегодня технологии Big Data уже входят в стандартную потребительскую ИТ-корзину любого среднего клиента. Уверен, что через два-три года технологии достигнут зрелости, и российские компании из самых разных отраслей будут иметь ясное понимание, каких данных и для чего они хотят.