















| Рубрикатор |  |
 |
| Статьи |  |
ИКС № 10 2006 | |
|
| Дж. СМИТ К. ФУЛТОН | 01 октября 2006 |
Как с помощью SLA повысить эффективность обслуживания
Традиционное управление уровнем обслуживания основано исключительно на мониторинге доступности ресурсов. Сервис (сеть, сервер или приложение) должен быть «живым» и «не падать» 99,999% времени. Такая оценка близка сердцу конечного пользователя, однако она не поможет достичь ключевых целей SLM, удовлетворить требования клиентских приложений и обеспечить постоянное улучшение характеристик. Причина проста: внешне «живой» сервис может иметь настолько низкие рабочие характеристики, что с ним невозможно работать. К тому же такой подход не только не способствует росту эффективности, но и приводит к обратному результату, фокусируя внимание администратора на редко происходящих событиях, а не на типичном поведении системы.О степени эффективности сервиса можно судить не по голому факту доступности или недоступности ресурса, а по конкретным рабочим характеристикам системы, сети, приложения. Нужно учитывать не только текущий статус оборудования и инфраструктуры, но и реальную практику работы конечного пользователя. И еще: применяемый способ должен экономить время обслуживания, а не увеличивать его.
К счастью, инструментарий SLM уже достиг уровня развития, способного удовлетворить всем этим требованиям. Современные методы SLM даже предлагают пути перехода от политики реагирования к превентивному управлению за счет применения четырех ключевых средств – многоуровневых отчетов, раннего обнаружения проблем, быстрого их разрешения и подбора вариантов способов управления.
Задаем и отслеживаем, или Параметры, критерии, переменные
Для эффективного управления SLM необходимо знать целевые параметры сервиса (Service Level Objectives, SLO), определяющие, какие цели конкретного бизнеса выступают в качестве критериев качества этой услуги. Принято оценивать три ключевые переменные: время отклика для конечного пользователя, время реакции сервера и задержку сигнала в сети. Способ их измерения может быть разным (пассивным или активным), но именно он определяет, будет ли достигнуто желаемое качество.
Сами параметры SLO могут определяться как средние значения по времени, как процентные соотношения средних значений или транзакций. Большинство представленных на рынке инструментальных средств работает с усредненными по времени значениями, которые не всегда отражают реальное состояние сервиса для большинства пользователей – скорее это что-то вроде «средней температуры по больнице».
Мониторинг SLO на базе процентного соотношения транзакций, напротив, с технической точки зрения точно соответствует реальной ситуации у пользователей. Однако на рынке практически нет решений, которые реализовали бы его в масштабах предприятия.
Еще один аспект контроля – настройка пороговых значений параметров SLO. Последние должны основываться на реальных потребностях пользователей, которые, по сути, различны для разных приложений и различаются в зависимости от метода доступа к сети. Нижнее пороговое значение показывает уровень, ниже которого пользователь начинает испытывать проблемы с сетью. Верхнее – указывает момент, когда недостаточная эффективность системы начинает приводить к существенным издержкам. Процентные соотношения (если система параметров SLO их поддерживает) должны уточняться по мере накопления опыта: это позволяет постоянно повышать эффективность и контролировать временны’е задержки.
Производительность для пользователя
Один из первых этапов реализации SLA – выбор ключевых переменных, на которых будет основана сама система соглашений об уровнях сервиса. В реальной жизни пожелания конечного пользователя чаще всего «качественные», и смысл их неоднозначен, хотя они так или иначе связаны с временем отклика системы. Специалисты же всегда хотят иметь «количественные» показатели, которые легко контролировать. Рассмотрим, как их представить для системы SLM.
Время отклика на запрос нужно отслеживать независимо от того, применяются ли соглашения SLA в системе или нет. Ведь самый простой способ выразить в цифрах ощущения пользователя от работы сети – измерить время транзакции и ее составляющих.
Для численной оценки решающее значение имеет и то, какие транзакции выбраны для измерения и как оно проводится. Если отслеживаются все типы операций, то для увеличения масштаба используется агрегирование, что уменьшит подробность данных; если только некоторые – потребуются время и силы на проверку репрезентативности результатов. Наиболее удовлетворительные результаты дает комбинация двух способов.
Нужно ли отслеживать в пассивном режиме реально существующих в системе пользователей или следует создать специальных агентов? Первое важно для достижения целей SLM, поскольку ради реальных пользователей все и делается. Зато второе позволяет получить детальную характеристику системы, что незаменимо для устранения неполадок в сети. Лучший вариант – комбинация пассивного мониторинга реальных пользователей и нескольких искусственно созданных агентов.
Производительность сервера
Время отклика сервера нужно отслеживать всегда, независимо от использования SLA, чтобы быстро определить, «виноват» ли сервер в ухудшении времени отклика на запрос или нет. Этот параметр можно использовать и для отслеживания качества сервиса, предоставляемого информационным центром, а также для оптимизации и планирования загруженности сети.
Однако при оценке времени отклика сервера возникают проблемы. Если для повторного выполнения одних и тех же транзакций используются искусственно созданные агенты, то результаты будут тоже искусственные, поскольку не связаны с реальным пользователем. Если кэширование информации производит сервер, ее нельзя обрабатывать и блокировать избирательно. А если транзакции выполняются в случайном порядке, теряется главное преимущество искусственно созданных агентов – детерминизм. Селективное кэширование при использовании искусственных агентов может дать неточную оценку времени отклика сервера. Но все эти беды устранимы при пассивном мониторинге характеристик сервера по всем транзакциям и всем пользователям.
Характеристики сети
Задержка сигнала в сети – еще один параметр, который необходимо отслеживать независимо от применения SLA-соглашений. Он позволяет быстро определить главное: в чем причина ухудшения времени отклика на запрос конечного пользователя. Показатели эффективности работы сети (например, время подтверждения приема) помогают также оценить качество сервиса, полученного от сетевого провайдера. Кроме того, непрерывный мониторинг задержки сигнала необходим для оптимизации и планирования работы сети.
Есть и общие методы оценки задержки сигнала в сети. К активным методам относится регулярная отправка пакетов ICMP (ICMP ping) и проверка сеансовых соединений TCP, к пассивным – подсчет либо сеансовых соединений TCP, либо пакетов приложений более общего назначения. Самые точные данные о производительности дает измерение задержки сигнала за счет отслеживания общих прикладных пакетов.

Чтобы оценить плюсы и минусы каждого метода, надо определить все составляющие задержки сигнала в сети, которая включает в себя пять компонентов: сериализацию (при преобразовании в последовательную форму), организацию очередей, передачу распространения сигнала в среде передачи, обработку данных и задержку протокола.
Сериализация – это время, необходимое для отправки всех битов пакета по среде передачи и зависящее от размера пакета и скорости доступа (для 64-байтного пакета при скорости 56 кбит/с – 18,3 мс, при скорости 256 кбит/с – 4,0 мс и при 1,5 Мбит/с – 0,7 мс, а для пакета в 1500 байт – 428,6; 93,8 и 16 мс соответственно). Сеансовые соединения TCP построены на 64-байтных пакетах. Основанные на них измерения почти всегда дают заниженную оценку для приложений. Пакеты ICMP можно сконфигурировать под любой размер, но он всегда одинаков в обоих направлениях. Большинство приложений такой симметрией не обладают, поэтому правильно зафиксировать задержку сериализации по конкретному приложению непросто. Кстати, по умолчанию пакет ICMP тоже 64байтный.
Задержка организации очередей – время, в течение которого пакет находится в буфере в ожидании своей очереди на передачу. Оно определяется задержкой сериализации для пакетов, обслуженных ранее, размером буфера, объемом перегрузки, а также конфигурацией маршрутизатора или правилами коммутации. Перегрузка может существенно измениться буквально за микросекунды, однако сеансы TCP можно открывать на секунды, часы и даже дни. Таким образом, задержка очередей, полученная опытным путем по сеансовым соединениям TCP, может сильно отличаться от задержки для основного приложения.
Это справедливо и для любой регулярной проверки вроде отправки запросов ICMP. Задержка очереди даже на 60 с может иметь мало общего с тем, что испытывает приложение. Вдобавок маршрутизатор или коммутатор часто помещают пакеты ICMP в очередь для привилегированной обработки, где скорость больше или меньше обычной. А для нее пакеты ICMP в моменты перегрузки часто вообще удаляются, а пакеты приложений переводятся в режим ожидания.
Итог: ICMP никогда не покажет длинных задержек. Если пакеты ICMP принудительно перемещены в начало очереди, задержка сократится, если окажутся в конце – возрастет, если только они вообще не удалятся.
Задержка распространения сигнала, или задержка по расстоянию, – это время, в течение которого пакет физически перемещается по среде передачи. Зависит оно только от расстояния и типа среды. Если сеансовые соединения TCP и пакеты ICMP используют тот же физический канал, что и пакеты основного приложения, то все задержки одинаковы. Однако нет гарантии, что у них одни и те же маршруты – если было бы так, то измерение ICMP никого бы не интересовало.
Задержка на обработку – время, которое требуется маршрутизатору или коммутатору для подготовки пакета к доставке и зависит от многих факторов, хотя и пренебрежимо мало по сравнению с другими задержками. Но надо помнить, что сеансовые соединения TCP могут потребовать большей обработки по сравнению с другими пакетами потока, а пакеты ICMP – меньшей.
Задержка по протоколу есть время ожидания пакета из-за использования базовых протоколов. Например, в совместно используемой среде пакет должен ждать, пока нужный узел не запросит доступ. Величина такой задержки зависит от протокола.
Итог: измерение сетевых задержек с помощью ICMР-запросов показывает только задержку, испытываемую отправителями пакетов ICMP в данный момент. Измерения сетевых задержек на базе сеансовых соединений TCP определяют лишь задержку для 64!байтных пакетов в момент начала сеанса (несколько секунд, часов или даже дней назад). В любом случае пассивное отслеживание пакетов главного приложения наиболее эффективно, поскольку оно отражает состояние работы пользователя.
Доступность сервисов
нужно отслеживать в явном виде – это часть стратегии управления SLM, причем традиционно отслеживается доступность и сети, и сервера. Для этого можно использовать активных агентов или программные зонды, которые периодически выполняют выбранные транзакции. Если такие средства настроены на запуск каждые 15 минут, то существенный сбой выявляется уже через 7–5 минут. Однако промежуточные кратковременные сбои могут остаться незамеченными и их не удастся отследить как параметр SLO. Более частый опрос, конечно, поможет обнаружить и их, но только за счет дополнительной нагрузки на систему.

Загадки статистики
Как уже отмечалось, важнейшее значение при реализации SLM-системы имеет выбор статистических параметров для оценки. Должны ли соглашения SLA базироваться на средних значениях по времени или на процентном отношении транзакций? Каков критерий, если увеличение, например, процентного отношения для успешных транзакций сокращает время отклика, предъявляя высокие требования к инфраструктуре? (Так, при SLA на основе средних для 95% по транзакциям время отклика не должно превышать 3 с.)
Основное преимущество выбора SLA на базе средних по времени в том, что почти каждый производитель систем SLM поддерживает их определение при развитом инструментарии. Увы, но временные средние не дают адекватного представления о реальной работе сети. Например, если девять пользователей имеют время отклика 0,5 с, а десятый – 90,0 с, то среднее составит 9,5 с, т.е. на целый порядок отличается от реальности для каждого.
Некоторые производители опираются на усеченное среднее значение, что снижает чувствительность к отдельным значениям-выбегам (отбрасывается любое измерение, превышающее порог). В предыдущем примере пороговое значение в 2 с приведет к тому, что усеченное среднее составит уже 0,5. Однако и здесь таится опасность: из-за отсечек могут быть упущены реальные проблемы с производительностью. Если время отклика для семи пользователей увеличивается с 0,5 до 2,5 с, то усеченное среднее по-прежнему останется 0,5, и это несмотря на то, что 80% пользователей столкнулись с ухудшением характеристик Из-за неоднородности большинства сред правильно выбрать пороговое значение для отсечки почти невозможно. Бывали случаи, когда из-за такого усечения участки с наихудшей производительностью выдавали отчеты чуть ли не с лучшими для всей сети показателями! Избежать этого позволяют соглашения SLA, основанные на процентном отношении транзакций. Если у 95% транзакций время отклика менее 3 с, то значения остальных 5% несущественны.
Почувствуйте разницу: соглашения SLA на базе усеченных средних игнорируют все значения времени отклика, превышающие предварительно установленный порог; если же все значения времени срабатывания превышают порог, то измерения как такового и вовсе нет. Соглашения же на основе процентного отношения транзакций игнорируют только заранее установленное процентное отношение (в нашем примере – 5%). Поэтому применение последних предпочтительнее, но тогда более ограничен выбор производителя системы SLM. С технической точки зрения отслеживать и давать отчет о процентном соотношении по сравнению со средними значениями – задача более сложная, потому и поставщиков немного. Некоторые производители выбирают гибридный метод составления отчетов, по процентному соотношению средних значений, а не транзакций. Соглашения SLA на базе такого гибридного метода потребуют, например, чтобы 95% из 5-минутных средних значений в течение месяца составляли менее 5 с.
Итог: соглашения SLA могут основываться на средних временны’х значениях, на процентном отношении временны’х средних или на процентном отношении транзакций. Первые дадут результаты со смещением, не отражающие реального сервиса пользователя. Вторые технически более совершенны, однако пока реализованы весьма ограниченным кругом поставщиков.
Как стать снайпером
Точное описание цели – залог хорошего результата. Сколько целевых значений нужно для каждой переменной и какие временные интервалы должны быть заданы для нее? Какие пороговые значения и процентные соотношения следует принять? Эти важные параметры определяются реальными потребностями пользователя.
Здесь есть два интересующих нас пороговых значения: порог значимости и критический порог. Все значения, которые меньше порога значимости, для пользователя незаметны, но это не означает, что они малы: просто величина задержек попадает в рамки ожиданий пользователя и не вызывает у него раздражения. Задержки, превышающие критический порог, приводят к тому, что пользователь фактически лишается сервиса. Они дорого обходятся бизнесу, провоцируя большие финансовые потери и снижение производительности труда служащих. Задержки, находящиеся между двумя описанными порогами, обычно воспринимаются пользователями как инерционность, «подтормаживание» приложения и сети.
Численные значения этих двух естественных порогов обычно заранее неизвестны, однако их можно оценить экспериментально, с помощью пользователей. Например, типичные задержки для загрузки веб-страниц – 3 и 8 с. Однако пороговые значения практически всегда сильно зависят от метода сетевого доступа и типа приложения. Так, пользователи, имеющие доступ к развлекательному порталу через спутник, спокойнее относятся к задержкам, нежели те, кто обращается с запросом в службу технической поддержки по наземному каналу DS3. Для каждого приложения и группы доступа необходимо задавать отдельное SLA-соглашение.
Следует помнить, что пользователи чувствительны не только к абсолютным значениям задержек, но и к их колебаниям, которые эффективно контролируются процентным соотношением в SLA. Например, пусть сначала соглашение SLA утверждает, что 95% времени работы отклик при транзакции должен быть менее 3 с, а 98% времени – менее 8 с. Улучшить качество сервиса может не снижение 3-секундного порога, поскольку это и так уже вполне приемлемое значение. Цель будет достигнута, если за определенный период времени эти цифры возрастут, скажем, до 96 и 99% соответственно.
Для этого может понадобиться намеренно исключить из соглашения SLA некоторые служебные окна или даже отдельных пользователей. Но такое «отсечение» должно вводиться в систему еще на стадии описания, а не после невыполнения соглашения SLA. Однако такие функции сегодня поддерживают далеко не все производители. Если выбранный продукт не в состоянии обеспечить исключение требуемых окон, то заданное процентное соотношение придется скорректировать вручную в меньшую сторону.
Подбор методов SLM-управления
Как уже отмечалось, система SLM должна активно поощрять переход от политики реагирования к упреждающему (превентивному) управлению. Решение, автоматизирующее SLM-управление, базируется на четырех группах функциональных возможностей: многоуровневых отчетах, раннем обнаружении проблем, быстром их решении и подборе вариантов управления.
Многоуровневые отчеты
Многие производители утверждают, что их инструментарий SLM полностью оставляет интерпретацию результатов и настройку на усмотрение пользователя. Уже сам факт отслеживания пакетов свидетельствует о применении SLM, но если время ограничено, это не всегда приносит эффект. От такого инструментария не слишком много пользы, если он обеспечивает лишь высокоуровневое «управление», не предоставляя подробных данных для выбора корректирующего действия. Инструмент SLM должен поддерживать переход от высокого уровня к техническим деталям, причем наиболее простым способом. Эту функцию называют навигацией, и именно она отвечает за получение иерархических отчетов.
Высокоуровневые сводки полезны, но используются, как правило, лишь для общения с нетехнической аудиторией. Цель же навигации – быстро добраться до нужного параметра в массе технических деталей, важных специалисту, принимающему решение.
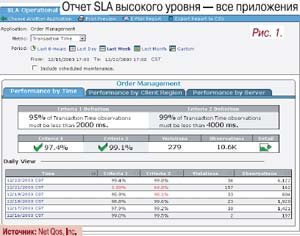
Отчеты SLA в качественном продукте должны поддерживать высокий, средний, низкий, а также интеллектуальный базовый уровни управления. Так, отчет SLA высокого уровня обычно показывает текущее состояние соглашений SLA для различных пользователей организации (рис. 1) и позволяет интерпретировать результаты в зависимости от «читателя» отчета. Если необходимо просмотреть более подробные данные, нужно щелкнуть на названии приложения, и на экране предстанет детальная сводка именно для этого приложения. Отчеты высокого уровня полезны для общей интерпретации результатов и идентификации нарушений, но их информации недостаточно для принятия решения и выбора конкретных корректирующих действий.
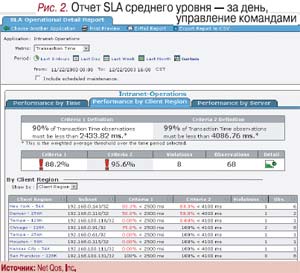
Отчеты среднего уровня показывают различные временны’е, пространственные или итоговые результаты реализации соглашений SLA, что позволяет быстро установить периодичность возникновения проблемы или определить временные интервалы для более глубокого исследования. Чтобы выявить «виновника» чрезмерного количества нарушений (отдельный сервер или группа пользователей), нужны другие варианты этих отчетов. Так, если нарушения соглашения SLA вызваны несколькими клиентскими сайтами, это станет очевидным благодаря отчету по клиентам (рис. 2). Подобное представление позволит ИТ специалистам понять, как привести приложение в желаемое состояние в соответствии с соглашениями SLA.
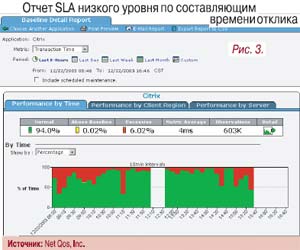
Отчеты низкого уровня нужны для быстрого решения проблем с производительностью и как вспомогательное средство для эффективного распределения ресурсов. Это, по сути, технические данные, отражающие масштаб и причины проблемы; они включают результаты автоматизированного анализа или подробные показатели производительности (рис. 3).
Но мало отслеживать производительность с помощью установленных порогов SLA, важно понять, как ее текущие значения меняются по сравнению с предыдущими. Ожидания пользователей основаны на опыте их работы с приложениями в прошлом: даже если система вполне соответствует принятым соглашениям SLA, можно столкнуться с их недовольством, вызванным, например, тем, что время срабатывания оказалось больше того, к которому они привыкли.
Специальный интеллектуальный отчет отражает базовую статистику производительности приложения с учетом производительности системы как в прошлом, так и за последнее время (рис. 4).
Чем раньше, тем лучше
Все и так знают привычные методы обнаружения проблем на предприятии: пользователи одолевают администраторов телефонными звонками и срочными сообщениями по электронной почте, а то и лично обращаются в службу ИТ. Но, как правило, такие службы не имеют физической возможности заниматься индивидуальными вызовами. Если источник проблемы не удалось обнаружить на ранней стадии, большую часть времени специалисты ИТ будут вынуждены тратить на пожарные меры в ущерб планированию развития системы и долговременным прогнозам.
Инструментарий SLM должен автоматически обнаруживать проблему в зародыше, т.е. до того, как она возникнет и станет видна невооруженным глазом. Разработки предыдущих поколений систем для обнаружения проблем используют предварительно сконфигурированные статистические пороговые значения, современный же инструментарий – самообучающийся алгоритм. Система изучает «стандартное» поведение приложений, серверов и клиентов, собирая и накапливая ежедневные, еженедельные и ежемесячные статистические данные. Она способна «понять», например, что последняя пятница месяца характеризуется более медленной работой, чем другие рабочие дни, поэтому не станет генерировать сигнал тревоги, если только режим работы не окажется совсем уж плохим по сравнению с «выученной» нормой.
Настраиваемая базовая статистика позволяет автоматизировать обнаружение возникающих проблем, а служба ИТ получит своевременное предупреждение о потенциальной опасности. Раннее обнаружение сокращает среднее время восстановления, повышает производительность труда и улучшает репутацию ИТ службы. Такая система осуществляет поиск проблем в масштабах всего предприятия, обнаруживая аномалии, выделяя неэффективно работающие участки и другие области, нуждающиеся в улучшении, обеспечивает мониторинг и анализ данных о производительности 24 часа в сутки 7 дней в неделю.
Очень важно уметь различать проблемы, связанные с доступностью, и проблемы с производительностью. Для этого обычно используют средства активного мониторинга, но у них есть некоторые недостатки. В «стандартном исполнении» они проверяют доступность (и производительность) ресурса периодически, например каждые 5, 15 или 30 минут. Если агенты настроены на проведение теста каждые 15 минут, проблема обнаружится в среднем через 7–5 минут (максимум через 15) после ее возникновения. Чем меньше установленный интервал, тем быстрее обнаружится проблема, но и тем больше нагрузка на сеть и серверы. Поэтому средства активного мониторинга обычно применяют для тестирования лишь отдельных транзакций из отдельных точек сети. Иначе агенты, которые должны обнаруживать определенные проблемы, своей работой могут спровоцировать их возникновение. Пассивный мониторинг в сочетании с периодически запускаемым активным исследованием более эффективен (например, активное обследование сети или сервера только при необычном отсутствии трафика).
Выявление, устранение, профилактика
Выбранный продукт SLM должен не только быстро обнаружить возникающие проблемы, но и помочь их устранить. Многоуровневая отчетность заметно облегчает эту задачу, особенно в сочетании с навигационным интерфейсом («щелкни и просмотри»). Пользовательские отчеты на основе конструктора форм – средство весьма гибкое, но интерфейс необычайно сложен, а работа – утомительна. Это средство скорее вспомогательное, чем основное. Режим автоматического исследования значительно экономит время, особенно при минимальной ручной настройке.
Одна из основных целей управления SLM – постоянное улучшение работы сети. Раннее обнаружение и быстрое решение проблем, несомненно, повышает эффективность работы. Но все это меры реагирования, а не профилактики. Сервис уже падает до неприемлемого уровня относительно порогового значения SLA или ощутимо ухудшается в сравнении с базовой статистикой по системе, когда включается диагностика. Если же сервис находится в устойчивом, но неэффективном состоянии, это может остаться незамеченным. Инструментарий SLM должен обеспечить механизм быстрого обнаружения всех неэффективно работающих компонентов сети и предложить варианты улучшения.
Диаграммы производительности (рис. 5) вообще чрезвычайно полезны: они позволяют выбрать из некоторого числа вариантов, включая приложение(я), клиента(ов), сервер (или группу), показатели, представляющие интерес, порядок сортировки и период времени. Так, проблемы взаимодействия в многоуровневом приложении ERP (системы планирования ресурсов предприятия) легко выявляются по этому моментальному снимку поведения каждой из составляющих: графический веб-интерфейс, справочник службы каталогов, обмен документами (NetBios/TCP), сервер баз данных (Oracle 9i) – и показывают их взаимное влияние.
Диаграммы производительности могут охарактеризовать латентное состояние сети предприятия, показать объем трафика для планирования нагрузки и провести сортировку проблем по уровням приоритетов. Гистограмма времени отклика сети по каждому клиенту иллюстрирует производительность всей сети, в схему включены все ее узлы, отсортированные по описанию. Например, пользователи виртуальной сети (VPN) испытывали недостаток производительности, в то время как пользователи в штаб квартире корпорации наслаждались высокой скоростью работы сети. Сортировку можно задавать по любому параметру.
Резюме
SLM-система – не просто способ гарантирования сервиса, но и инструмент настройки информационных технологий на требования бизнеса. Однако для правильной реализации программы работы необходимо выполнить два требования: 1) технические цели должны быть четко определены, 2) служба ИТ должна научиться работать стратегически. При определении технических целей надо учесть все сервисы, которые подлежат мониторингу, выбрать показатели для измерений, методы измерения и инструментарий для применения соглашений SLA. Выбранные средства SLM должны поддерживать превентивное управление за счет использования четырех ключевых факторов многоуровневых отчетов, раннего обнаружения проблем, быстрого их решения и подбора других вариантов.
Управление SLM дает возможность специалистам ИТ циклически улучшать сервисы, а анализ производительности и статистики соответствия сети требованиям за прошлые периоды времени позволяет идентифицировать проблемные области, реорганизация которых обеспечит максимальное улучшение обслуживания.
Заметили неточность или опечатку в тексте? Выделите её мышкой и нажмите: Ctrl + Enter. Спасибо!