













| Рубрикатор |  |
 |

| Статьи |  |
ИКС № 01-02 2015 | |
|
| Петр РОНЖИН Василий КАЗАКОВ | 09 марта 2015 |
Надежность, отказоустойчивость, доступность. Синонимы или?..
Заказчики часто весьма туманно формулируют свои требования к дата-центрам. Их нужно переформулировать в терминах, которые можно зафиксировать в техническом задании.
 |
 |
Бывает, что требования излагаются примерно в таком виде: «Наш банк работает с очень серьезными клиентами, поэтому ЦОД должен работать всегда». Ну что делать? Мы принимаем эти требования и начинаем переводить их на язык техзадания, попутно объясняя, что понадобится внести серьезные изменения в предварительные проектные решения по инженерным системам.
Дадим некоторые пояснения к терминам, которыми мы пользуемся для достижения проектных показателей надежности, отказоустойчивости и доступности дата-центров. Речь пойдет об инженерных системах ЦОДа, хотя в принципе то же самое относится и к ИТ-оборудованию. Только полный анализ показателей всей инфраструктуры дата-центра может дать адекватную картину уровня доступности объекта.
Братья, почти близнецы MTBF, MTTF и MTTR
Два ключевых показателя в инженерных системах – это среднее время между отказами (Mean Time Between Failures, MTBF) и среднее время ремонта (Mean Time To Repair, MTTR):
MTBF = Общее время непрерывной работы
количество отказов
MTTR = Общее время простоя
количество отказов
Среднее время ремонта – среднее время, необходимое для ремонта устройства после отказа.
| Б е з к о н с у л ь т а н т а н е о б о й т и с ь |
|
Денис СИВЦОВ, менеджер проектов подразделения IT Business, Schneider Electric
Большинству заказчиков, в особенности владельцам корпоративных ЦОДов, довольно затруднительно самостоятельно сформулировать четкие требования к отказоустойчивости создаваемых ими дата-центров. Как правило, это обусловлено тем, что не всегда есть ясное понимание того, насколько бизнес зависит от конкретных ИТ-сервисов и какие потери будет нести компания в периоды, когда тот или иной сервис не работает. В результате в процессе проектирования могут возникнуть сложности с определением необходимого уровня доступности ИТ-оборудования, на котором функционируют соответствующие сервисы. Это приводит к тому, что зачастую невозможно корректно задать требования к отказоустойчивости инженерной инфраструктуры ЦОДа, которая должна обеспечить работоспособность данного оборудования. В такой ситуации для разработки детального ТЗ заказчик может выбрать один из следующих вариантов:
Стоит отметить, что рекомендации Uptime Institute не привязаны ни к стране, ни к климату, ни к каким-либо другим характеристикам окружающей среды, в которой работает ЦОД. Они формулируются исходя из требований бизнеса к надежности инженерной инфраструктуры или к ЦОДу. Причем необходимо уделять внимание отказоустойчивости не только ЦОДа, но и ИТ-инфраструктуры в целом, поскольку нет смысла в суперотказоустойчивом ЦОДе при неработающей ЛВС или каналах связи и т.п. Рекомендации Uptime Institute универсальны, и их требования иногда могут оказаться избыточными. Поэтому в некоторых случаях частью требований можно пренебречь без ущерба для отказоустойчивости ЦОДа (и тем самым немало сэкономить), так как вероятность некоторых отказов в конкретном дата-центре может быть крайне мала. Но чтобы определить возможность такого отступления от требований, безусловно, необходимо привлекать консультанта, который хорошо разбирается в рекомендациях Uptime Institute и обладает опытом строительства ЦОДов с похожими характеристиками и в условиях, аналогичных тем, в которых будет создаваться новый дата-центр.
Существуют классические методики анализа надежности инженерных систем, которые использовались раньше при создании сложных комплексных технических решений (ракет, вычислительных центров и т.п.). Тогда при проектировании, например, конкретного вычислительного центра производился расчет необходимой надежности каждой его подсистемы исходя из требований заказчика и с учетом окружающих условий. Сейчас в большинстве случаев при строительстве ЦОДов вместо подобных методик применяются универсальные рекомендации и стандарты. Это удешевляет и ускоряет проектирование, но ухудшает соотношение между результирующим уровнем надежности инженерных систем и затратами, связанными с реализацией данного уровня надежности. Поскольку оборудование со временем становится дешевле, а инжиниринговые услуги -- дороже, то такая практика делается общераспространенной.
Стоит также отметить, что разные типы заказчиков обычно предъявляют разные требования к надежности своих ЦОДов (корпоративным и коммерческим дата-центрам). В коммерческих ЦОДах отказоустойчивость напрямую влияет на доходы заказчика, поэтому требования к ней значительно выше, чем в корпоративных ЦОДах. Хотя иногда высокий уровень надежности требуется и от некоторых корпоративных дата-центров (например, от ЦОДов банков, бирж и т.п.). В любом случае,
когда при создании ЦОДа хочется найти компромисс между затратами и
отказоустойчивостью, следует привлекать опытных консультантов, которые в каждой
ситуации могут подобрать наиболее эффективное решение для конкретного
заказчика. |

Для тех объектов, которые не могут быть отремонтированы и просто заменяются новыми, применяется термин «средняя наработка до отказа» (Mean Time To Failure, MTTF). По сути, это среднее время, которое проработает устройство до того момента, как сломается. Для ремонтопригодных устройств среднее время между отказами можно определить как сумму MTTF и MTTR (см. рисунок). Другими словами, средняя наработка на отказ – это среднее время от начала одного сбоя до начала другого. Это различие между терминами важно, если время ремонта составляет значительную часть общего времени работы устройства.
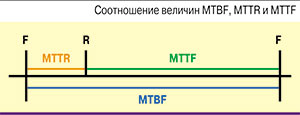
Например, для лампочки в светильнике наиболее подходящий показатель – MTTF, так как она ремонту не подлежит. Для светильника же будет применяться MTBF, поскольку замену лампочки можно считать ремонтом светильника. Но MTBF светильника почти равен MTTF лампочки, поскольку ее замена производится всего 0,0167 ч, а ее ресурс – целых 10 000 ч. Таким образом, MTBF = MTTF (10 000 ч) + MTTR (0,0167 ч) = 10 000,0167 ч. Как видите, разница незначительна.
Другой пример: без замены масла в двигателе автомобиля поломка может произойти после 500 ч езды по шоссе – это MTTF. Если предположить, что на замену двигателя потребуется 12 ч (MTTR), то среднее время между отказами автомобиля из-за поломки двигателя (MTBF) составит 512 ч.
Большая часть технологического оборудования, подобно автомобилям, в случае поломки будет отремонтирована, а не заменена, поэтому в контексте надежности оборудования ЦОДа показатель «среднее время между отказами» больше всего подходит для измерений.
Что такое отказ?
Термин «отказ» может употребляться в нескольких значениях.
Например, источник бесперебойного питания выполняет пять функций в двух состояниях. Когда основное питание доступно, он 1) позволяет защитить питание от основного источника к машине; 2) стабилизирует питание путем ограничения скачков или колебаний; 3) запасает энергию в аккумуляторе до полного заряда батареи. Когда основное питание прерывается, ИБП 4) защищает поставку непрерывной мощности к машине; 5) подает сигнал, указывающий, что основное питание выключено.
Нет никаких сомнений, что происходит отказ, если ИБП прекращает защиту основного питания машины (функция 1). Отказы для функций 2, 3 или 5 могут быть неочевидными, так как «защищенная» машина по-прежнему работает на основном питании или питании от батареи. Даже если эти сбои заметили, меры по их устранению могут не быть приняты незамедлительно, так как «защищенная» машина все еще работает и ее работа может быть важнее, чем ремонт или замена ИБП.
Что такое доступность?
Доступность устройства для запланированного рабочего времени математически выражается отношением общего времени, когда оборудование находится в работоспособном состоянии, к общему времени эксплуатации.
Автомобиль в приведенном выше примере имеет доступность 500 / (500 + 12) = 97,66% времени. Ремонт является внеплановым простоем. С плановой получасовой заменой масла каждые 250 ч, когда индикатор на приборной панели предупреждает водителя, доступность увеличится до 250 / (250 + 0,5) = 99,8%. Если замена масла производится по расписанию как мероприятие по техническому обслуживанию, да еще с предоставлением подменного автомобиля, то доступность передвижения на автомобиле достигнет 100%.
Почему это важно? Доступность – это ключевой показатель производственного процесса; он является частью метрики «общая эффективность оборудования» (OEE). Производственное расписание, которое включает в себя время простоя для профилактического обслуживания, может точно предсказать общий объем производства. Графики, которые игнорируют среднюю наработку на отказ и среднее время ремонта, – это просто будущие бедствия, ожидающие ликвидации.
Как рассчитать фактическое среднее время между отказами? Фактическая или историческая средняя наработка на отказ рассчитывается с помощью наблюдений в реальной ситуации (существует отдельная дисциплина для разработчиков оборудования, базирующаяся на компонентах и предполагаемом уровне нагрузки). Расчет фактического среднего времени между отказами требует множества наблюдений, для каждого из которых должны определяться:
Uptime moment (u)– момент времени начала работы оборудования (изначально или после ремонта);
Downtime moment (d) – момент времени, в который оборудование сломалось после начала работы.
Время между отказами (TBF) – это, соответственно, разность d – u.
Для расчетов необходима совокупность пар моментов ui и di (i изменяется от 1 до n, где n – количество наблюдений). Среднее время между отказами рассчитывается по формуле:
MTBF = ∑ (di – ui) / n.
Вспомним теперь, из чего состоит инженерная инфраструктура дата-центра: многочисленные системы питания, системы охлаждения/кондиционирования, системы дренажа, системы освещения и т.д. Каждая система, в свою очередь, состоит из множества элементов, которые имеют свои показатели времени наработки на отказ. Таким образом, чем сложнее инженерная инфраструктура дата-центра, тем больше в ней будет возникать отказов. Именно поэтому надо стремиться к разумному упрощению систем.
Что же такое надежность?
Надежность – это свойство оборудования (системы) сохранять значения установленных параметров функционирования в определенных пределах, соответствующих заданным режимам. Надежность – комплексный параметр, который в зависимости от назначения системы и условий ее эксплуатации может включать в себя безотказность, долговечность, ремонтопригодность и доступность как в отдельности, так и в разных сочетаниях. Работоспособность – это состояние системы, при котором она соответствует всем требованиям, предъявляемым к ее основным параметрам. Показатели могут со временем меняться. Изменение, выходящее за допустимые границы, приводит к возникновению отказа. Долгое время надежность не измерялась количественно, что сильно затрудняло ее объективную оценку. Для оценки использовались качественные определения – «высокая», «низкая» и др. Установление количественных показателей и способов их измерения и расчета положило начало научным методам в исследовании надежности.
Количественные показатели надежности определяются путем расчетов, проведением испытаний, статистической обработкой данных эксплуатации и математическим моделированием. Расчеты надежности производятся главным образом на этапе проектирования с целью прогнозирования ожидаемой надежности данной системы. Это позволяет выбрать наиболее подходящий вариант технического решения и методы обеспечения надежности, выявить слабые места, обоснованно назначить рабочие режимы, форму и порядок обслуживания системы.
Надежность можно повышать разными способами:
- использованием новых элементов, обладающих повышенной надежностью;
- принципиально новыми конструктивными решениями;
- резервированием;
- выбором оптимальных рабочих режимов и эффективной защиты от неблагоприятных внутренних и внешних воздействий;
- эффективным контролем, позволяющим не только констатировать техническое состояние и установить причины возникновения отказа, но и предсказывать будущее состояние с тем, чтобы предупреждать возникновение отказов.
- Интересно, много ли читателей данной статьи на практике сталкивались с расчетами надежности проектируемой инженерной инфраструктуры ЦОДа? Мы – ни разу…
Необходимость и избыточность
Все вышеописанные расчеты подробно рассматриваются в двух десятках ГОСТов серии 27 «Надежность в технике». Как мы с вами понимаем, такие расчеты по надежности ЦОДа чрезвычайно трудоемки, поскольку компонентов в системе жизнеобеспечения ЦОДа много, а добыть информацию о MTBF, MTTR и MTTF для каждого элемента почти невозможно.
Авторам доводилось бывать на немецком заводе холодильного оборудования. И на вопрос о MTBF холодильной машины им ответили, что такой параметр известен только для одного из компонентов машины.
Поскольку мы инженеры, нам часто приходится действовать как в анекдоте про физика, математика и инженера, которым поручили найти объем красных резиновых шаров, и физик объем измерил, математик вычислил, а инженер посмотрел в таблице. Применительно к ЦОДам есть свои «таблицы объема красных резиновых шаров» – это стандарты обеспечения доступности и отказоустойчивости. Наиболее известны документы Uptime Institute Tier Standard: Topology и Operational Sustainability. Первый документ говорит о проектировании ЦОДа, второй – о его обслуживании. Кроме того, существуют и другие системы классификации ЦОДов по уровню надежности.
Некоторые системные интеграторы мирового масштаба не поддержали концепции и критерии Tier Standard: Topology. Они сочли, во-первых, что критерии Uptime Institute зачастую слишком категоричны и не учитывают многих факторов, специфичных для конкретного ЦОДа, и во-вторых, что наработки и информацию, накопленные ими за долгое время, следует хранить внутри компании, так как это ее интеллектуальная собственность. Этот довод понятен; посмотрим, какие же факторы должны браться в расчет при определении требуемого уровня надежности.
Прежде всего – бизнес-задачи заказчика. У разных заказчиков задачи различаются, как различаются требования к ЦОДу провайдера, ЦОДу поисковой системы, коммерческому ЦОДу, ЦОДу банка, суперкомпьютера и т.д. К примеру, для ЦОДа поисковой системы главное – доступность информации. Крупный поисковик при нештатной ситуации в одном ЦОДе может распределить запросы на другие работающие ЦОДы, при этом конечный пользователь разницы в качестве предоставления услуги не заметит. Другая ситуация может возникнуть в ЦОДе суперкомпьютера, где в зависимости от ситуации может появиться возможность снизить мощность ИТ-оборудования без прерывания технологического процесса. То есть необходимо разбираться, где конкретно должна быть обеспечена надежность – на уровне инженерных систем, на уровне ИТ-оборудования, на уровне информации или на каком-либо ином уровне.
Второй фактор – локализация заказчика. В зависимости от местных норм и правил требования к системам ЦОДа могут меняться. Так, пытаясь выполнить и локальные нормы, и требования Uptime Institute, можно получить ЦОД с двумя независимыми городскими вводами и резервированием 2N по дизель-генераторным установкам, что, на наш взгляд, избыточно.
Как видим, достаточная надежность может быть обеспечена разными способами и подходами, не всегда традиционными и лежащими в рамках стандартов, но менее затратными и не такими сложными. И из всего вышесказанного можно сделать достаточно банальный, но трудный в реализации вывод. Если вы собираетесь построить оптимальный по надежности и стоимости ЦОД, наиболее рациональным подходом будет максимальное упрощение инженерной инфраструктуры и уменьшение количества элементов в каждой системе.